여러가지 자료구조 (Data Structure)
여러 가지 자료구조에 대해 알아봅시다.
JDK안에 우리가 구현할 자료구조에 대한 여러 가지 클래스가 구현되어있지만,
이런 원리로 구현되어있구나 확인
모든 걸 다 볼 순 없고
선형 자료 ( 배열 / 리스트 /스택 / 큐 )
비선형 자료 (트리 / 그래프 / 해싱 )
정도 살펴보고 구현해보기!
자료구조란 무엇인가? (Data Structure)
- 프로그램에서 사용할 많은 데이터를 메모리 상에서 관리하는 여러 구현 방법들
- 회원정보(id, name 등)들은 보통 DB에 있을 텐데 DB에 있는 정보들을 꺼내면 메모리에 있게 된다. 이 메모리에 있는 것들을 화면에도 뿌려주고 리포트도 만들고 하는데, 그것들을 어떻게 관리해야 효율적인지 최적인지
- 효율적인 자료구조가 성능 좋은 알고리즘의 기반이 됨
- 자료의 효율적인 관리는 프로그램의 수행 속도와 밀접한 관련이 있음
- 여러 자료 구조 중에서 구현하려는 프로그램에 맞는 최적의 자료구조를 활용해야 하므로 자료구조에 대한 이해가 중요함
- 어떤 자료구조가 있고, 그 자료구조들이 어떤 특징이 있고, 무엇을 위한 자료구조인지 알아야 할 필요 있다.
- jdk에 이미 많이 구현되어있어서 직접 구현할 일은 별로 없지만 어떤 구조인지 특징을 가지고 있는지 알아야 한다.
자료구조에는 어떤 것들이 있나? - 선형 자료구조와 비선형 자료구조
- 한 줄로 자료를 관리하기 (선형 자료구조)
- 선형 자료구조 (배열 / 연결 리스트 / 스택 / 큐 ) 앞과 뒤의 요소가 1:1의 관계
- 비선형 자료구조 ( 트리 / 그래프 / 해싱 )
선형 자료구조
배열 (Array)
선형으로 자료를 관리, 정해진 크기의 메모리를 먼저 할당받아 사용하고, 자료의 물리적 위치와 논리적 위치가 같음
배열 큰 특징
중간이 비면 안 됨. 물리적 위치와 논리적 위치가 같으므로! - 1번 뒤에 2번 식으로 메모리상에도 존재
비어있으면 뒤에 거를 당겨오고 / 끼어넣을 거면 뒤로 밀어주고 코드 필요
어느 위치에 있는 요소를 빼오는 것이 빠르다. ( 물리적 논리적 위치가 같아서 )
a 배열에서 2번째 요소를 꺼낼 거다
a [2] 4바이트씩 이니까 a [2] = 10 + 4*2 = 18 해서 주소 값 18 위치한 거 빨리 꺼내올 수 있음.

배열은 -> 처음에 쓰기 전에 10개면 10개 때리고 들어간다. 물리적으로 size 할당받아서 사용하는 반면,
연결 리스트 (LinkedList)
- 선형으로 자료를 관리,
- 자료가 추가될 때마다 메모리를 할당받고, 자료는 링크로 연결됨.
- 자료의 물리적 위치와 논리적 위치가 다를 수 있음
배열에서는 자료를 가지고만 있으면 된다. 링크드 리스트에서는 자료뿐 아니라 다음 엘리먼트를 가리키는 링크를 가지고 있다. ( java에서는 객체의 참조 변수 가리키도록 구현 )
우리 반에는 30명이 들어올 거야 - 배열 - 번호대로 앉는다
우리 반에는 전학 올 때마다 책상을 가져와서 추가해줄 거다 - 링크드 리스트 - 아무 데나 앉는다.
+@
전에 오는 엘리먼트를 가리키는 더블 링크드 //
마지막에는 가리키는 애가 없는 null인데 맨 처음을 가리키게 하는 서클 링크드도 있다.
리스트에 자료 추가하기

리스트에서 자료 삭제하기

미뤄주거나 당겨주는 작업 필요 없이 그냥 다음은 너다 그다음은 너다 지정 - 링크 연결만 수정하면 된다.
배열보다 자료 추가/제거 속도가 빠름
배열은 추가 / 제거 속도가 느리다. 대신 기준이 되는 몇 번째 애를 찾는데 시간은 빠르다.
링크드 리스트는 추가 / 제거 속도가 빠르다. 대신 기준이 되는 몇 번째 애를 찾는데 시간이 오래 걸린다.
스택 (Stack)
가장 나중에 입력된 자료가 가장 먼저 출력되는 자료 구조 (Last In First OUt) (후입 선출)
top에서만 추가와 삭제가 이루어짐
스택 메모리
a()
main() a() 함수 다 써야지 main() 함수로 돌아온다.
가장 최근의 데이터를 꺼낸다 라던지 - 바둑 /장기/ 체스 무르기 기능할 때. - 깊이 우선 탐색할 때 사용

큐 (Queue)
가장 먼저 입력된 자료가 가장 먼저 출력되는 자료 구조 (First In First Out) (선입선출)
선착순 front - rear
자료 추가는 rear 부분에서만 가능 // 꺼내지는 것은 front 부분에서만 가능
자료 추가는 enqueue // 꺼내는 거는 dequeue
앞에서 자꾸 빠지면 메모리가 비는데 이것을 당기지는 않고 /
배열로 구현하면 front 가 점점 rear 쪽으로 오면 메모리 낭비
원형으로 구현하면 - 서큘러 큐 - 메모리 낭비 줄일 수 있다.

스택 하고 큐는 어레이와 링크드 리스트로도 // 2가지 모두 구현할 수 있다.
여기서부터는 비선형 자료구조 ( 트리 / 그래프 )
트리 (Tree)
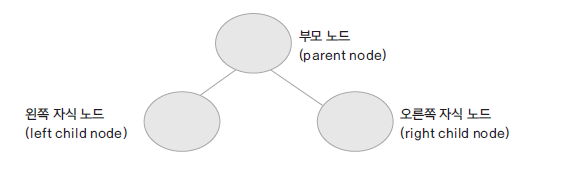
부모 노드와 자식 노드 간의 연결로 이루어진 자료 구조
패런츠 노드 / 차일드 노드
차일드가 몇 개냐 - 디그리 (차수)
프로그램에서 가장 많이 쓰는 트리는 이진트리 <=2 (0~2개)
힙(heap)
Priority queue를 구현 (우선 큐)에 힙 사용
Max heap : 부모 노드는 자식 노드보다 항상 크거나 같은 값을 갖는 경우
Min heap : 부모 노드는 자식 노드보다 항상 작거나 같은 값을 갖는 경우
heap정렬에 활용할 수 있음 - 루트를 계속 꺼내게 되면 - 가장 큰 수가 계속 꺼내짐 heap sort
루트 엘리먼트 ( 제일 위에 노드 ) 부모 노드
트리가 채워질 때 왼쪽부터 채워진다. 완전 이진트리 /
부모 노드 >= 차일드 노드 - max heap
부모 노드 <= 차일드 노드 - min heap
이진트리 (binary tree)
부모 노드에 자식 노드가 두 개 이하인 트리
이진 검색 트리 (binary search tree)
힙은 요소가 중복돼도 상관없음 어느 개 위로 올라가도 상관없었다.
이진 검색 트리는 검색을 위한 목적으로 만들어졌다.
중복되면 안 됨

자료(key)의 중복을 허용하지 않음
왼쪽 자식 노드는 부모 노드보다 작은 값, 오른쪽 자식 노드는 부모 노드보다 큰 값을 가짐
자료를 검색에 걸리는 시간이 평균 log(n) 임
inorder traversal 탐색을 하게 되면 자료가 정렬되어 출력됨예) [23, 10, 28, 15, 7, 22, 56] 순으로 자료를 넣을 때 BST

22를 찾겠다 -> 23보다 작으므로 왼쪽 -> 10과 비교 : 크니까 오른쪽 -> 15와 비교 : 오른쪽
자료 검색 속도가 빠름 : 일렬로 있을 때는 한 개 한 개씩 비교를 해야 되는데이진 검색 트리 구성해놓으면 1번 비교할 때마다 비교해야 될 요소 수가 반씩 날아간다 -> 속도가 빠르다 -> 평균 속도 log2에 n
트리나 그래프의 엘리먼트들을 쭉 돌아본다는 것을 순회한다 -> 트리를 traversal 한다.
여러 traversal 방법 중 inorder traversal -> 루트 부모를 기준으로 left를 보고 현재 부모 노드를 보고 right를 보고
inorder traversal -
{ left 있으면 left로 이동 left 없으면 자기 자신 찍고 부모 노드로 이동 -> 부도 노드 찍고 right로 이동 후 반복 }
-> 하면 정렬되어 출력됨 7, 10, 15, 22, 23, 48, 56 -> TreeSet이나 Treewep 도 이런 식으로 구성
jdk 클래스 : TreeSet, TreeMap (Tree로 시작되는 클래스는 정렬을 지원함)
그래프
응용분야 : 내비게이션이나 구글맵 같은 거
그래프 (Graph)란 - 정점과 간선들의 유한 집합 G = (V, E)
정점(vertex) : 여러 특성을 가지는 객체, 노드(node)
간선(edge) : 이 객체들을 연결 관계를 나타냄. 링크(link)
간선은 방향성이 있는 경우와 없는 경우가 있음
-> 있는 경우 :: 웨이트 값만큼 걸림 :: 거쳐 오는 길 있으면 웨이트 다 더해서
-> 없는 경우 :: 양방향 웨이트 똑같다는 뜻으로 어디로든 갈 수 있다.
그래프를 구현하는 방법 : 인접 행렬(adjacency matrix), 인접 리스트(adjacency list)
그래프를 탐색하는 방법 : BFS(bread first search), DFS(depth first search)
- BFS : 자기로부터 인접 노드들을 먼저 볼 것이냐
- DFS : 인접 노드를 따라가면서 먼저 보고 되돌아올 것이냐
그래프의 예)

동그라미 안에 0,1,2,3, 쓰여있는 애들 -> 노드 또는 vertex라 고함
노드와 노드를 연결해주는 애를 -> 엣지 또는 링크라고 함 ( vertex 엣지라는 표현 많이 씀/ 트리에서는 노드라는 표현 많이 씀)
그래프 구현 내용은 알고리즘 쪽에서 다시 설명 ---
jdk 클래스 : TreeSet, TreeMap (Tree로 시작되는 클래스는 정렬을 지원함)
해싱 (Hashing)
자료를 검색하기 위한 자료 구조
검색을 위한 자료 구조
키(key)에 대한 자료를 검색하기 위한 사전(dictionary) 개념의 자료 구조
key는 유일하고 이에 대한 value를 쌍으로 저장 -> 키도 가지고 value도 가진다.
index = h(key) : 해시 함수가 key에 대한 인덱스를 반환해줌 해당 인덱스 위치에 자료를 저장하거나 검색하게 됨
->순서대로 들어가는 것이 아니다.
값이 중복되는 경우 발생할 수 있다. 그런데도 인덱스 연산이 산술적으로 가능하고 빨라서 사용한다.
해시 함수에 의해 인덱스 연산이 산술적으로 가능 O(1)
저장되는 메모리 구조를 해시 테이블이라 함
jdk 클래스 : HashMap, Properties ( Dao 예제에서 사용했던 )
예제 상황 ) 극장이 있다. 좌석표가 0번부터 ~ 99번까지 100개의 좌석
관객이 꽉 차지 않아서 표를 1-300번까지 300장의 표를 팔았다.
관객을 어떻게 앉힐 것인지? 오는 순서대로 차례대로 앉혀도 되지만
표의 번호가 55번이다 할 경우 55%100 하면 나머지 55 -> 55번 좌석에 앉힌다.
표의 번호가 123번이다 할 경우 123%100 하면 몫은 1 나머지 23 -> 23번 좌석에 앉힌다.
해쉬 펑션은 %100 // 결과인 인덱스 값 55위치에 자료 값 저장
155번이 오면 같은 55번 자리에 앉게 된다. 중복되면 옆자리 앉게 해주는 방법도 씀.
중복되는 경우 해결 위해 ( 해쉬 펑션 값이 잘 분산되고 겹치지 않도록 복잡하게 잘 짜기 / 해시 테이블 /
해시 테이블

중복되는 경우 발생 - 옆자리에 앉힌다.
23/ 123/ 223 /323 이웃관계되고 여기서 찾으면 됨. - 배열로 만들어지는 효과
버켓 슬롯 커질수록 안 쓰는 공간과 메모리 너무 많아진다.
링크드 리스트로 체이닝으로 만든다.
체이닝은 구현 과정 복잡. 시간 더 걸림
체이닝

자료구조는 대학 한 학기의 분량이므로 전반적으로 살펴보기만 했다.
뒤에서 대표적인 것들 몇 가지 구현해보기로 하자!
review
자료구조
DB에 있는 정보들을 꺼내면 메모리에 위치 - 이 메모리들을 어떻게 관리해야 효율적인지 최적인지
구현하려는 프로그램에 맞는 최적의 자료구조를 활용해야 하므로 자료구조에 대한 이해가 중요하다.
크게 2가지 선형 자료 (배열 / 리스트 / 스택 / 큐 )
비선형 자료(트리 / 그래프 / 해싱 )
자료구조에 대해 무엇이 있는지 가볍게 쭉 살펴보았다.
배열 부분은 앞에서도 다뤘던 내용과 겹쳐서 친숙했지만
나머지 부분들은 생소하기도 하고 어떻게 활용하는지 써보지 못하였다.
자료구조에 대해서만 한 학기를 배운다니 wow
대표적인 몇 가지들을 뒤에서 배우고 활용하는 것도 배울 예정이다.
자료 구조 클래스들을 어떻게 구현하는지도 알아야겠지만
어떤 원리로 구현되어있고, 어떤 상황에서 사용하는지에 더 포커스를 맞춰서
이해하는 것이 중요한 것 같다.