함수 사용해보기!
- 일반적으로 SELECT 절 WHERE절에서 사용한다.
- 되게 많은데. 굳이 안 해도 검색해서 찾을 수 있다~
- String.charAt() / indexOf() 이런 것들 java에서 이미 만들어놓은 메서드 활용했듯이
- Oracle에서도 - 누군가가 만들어놓은 함수를 사용하는 것
- dual 테이블 활용해서 진행!
[ 문자열 , 숫자 , 날짜 , 타입 변환, NULL처리, 조건문, 순위 , 집계, 그룹 ] 함수
[ 문자열 함수 ]
1. SUBSTR : 문자열 자르기
- SUBSTR( '문자열' , 시작 위치, 개수 )
- 개수 생략 가능
2. CONCAT : 문자열 연결
- CONCAT( '문자열' , '문자열' )
- 'ABC' || '심원용' <- 이랑 같은 결과
3. TRIM : 공백 제거
- 문자열 사이의 공백은 제거 불가능( java도 마찬가지 )
- TRIM( ' ABC ' )
- TRIM : 공백 제거 (양쪽)
- LTRIM : 왼쪽 공백 제거
- RTRIM : 오른쪽 공백 제거
4. LOWER / UPPER :
- 소문자로 변경 / 대문자로 변경
- LOSER('ABC') / UPPER('abc')
5. REPLACE : 대체하다
- REPLACE('ABC', 'B', 'X' )
- 결과 - AXC
6. PAD : 원하는 사이즈만큼 빈칸을 공백으로 채워줌
- 빈칸을 공백으로 채워주겠다. -기본
- 내가 지정한 문자로 공백을 채워주도록 해줄 수도 있다
- PAD
- LPAD : 왼쪽에 적용
- RPAD : 오른쪽에 적용
- LPAD('ABC', 5) == 출력 결과 ==> [[공백][공백]ABC] -- 5 SIZE로 출력
- 10개로 하면 ABC 빼고 7개 공백으로 채워준다.
- RPAD('ABC', 5, '#') == 출력 결과 ==> ABC##으로 5 SIZE출력
7. INITCAP : 첫 글자를 대문자로 바꿔줌
- 거의 사용 안 한다.
- INITCAP('abc') == Abc출력
8. INSTR : 특정 문자열 존재하는지 확인
- 몇 번째 위치하는지를 결과로 알려준다.
- -없는 거 입력하면 0 출력 --- 0보다 큰 값 출력되면 포함되고 있구나 체크 가능
- INSTR('ABCDEFG', 'CD') == 출력 결과 ==> 3 출력
- 몇 번째부터 탐색할지
- 몇 번째 포함되는 글자를 나타낼지 지정 가능
- SELECT INSTR('ABCDEFG123KH1234KH12345' , 'KH', 5, 2) == 출력 결과 ==> 15
- KH라는 글자가 포함되는지 / 5번째부터 탐색 시작 / 2번째 포함하는 KH의 위치 출력
[ 숫자 함수 ]
JAVA에서 MATH 함수 사용한 것이랑 비슷
1. ABS : 절대값
- ABS(-123) ==== 출력 결과 ===> 123
2. ROUND : 반올림
- ROUND( 3.14, 1 ) ==== 출력 결과 ===> 3
- 몇 번째 소수점 자리까지 표현할지 지정 가능
3. TRUNC : 몫을 구하는 함수
- 오라클에서는 [ / ] 연산은 나누기 계산이다. ---- JAVA에서는 몫을 구하는 연산이지만
- 몫을 구하기 위해서 TRUNC 함수 사용 + 자릿수도 지정가능
- TRUNC( 10/3, 3 ) ==== 출력 결과 ===> 3.333
4. MOD : 나머지 구하는 함수
- MOD( 10, 3 ) ==== 출력 결과 ===> 1
5 POWER : 제곱하는 함수
- POWER( 2, 3 ) ==== 출력 결과 ===> 8
6. SQRT : 제곱근
- SQUT( 25 ) ==== 출력 결과 ===> 5
[ 날짜 함수 ]
- SYSDATE
- SYSTIMESTAMP
- CURRENT_TIMESTAMP
- CURRENT_DATE
요새는 SYSDATE도 잘 안 쓰는 추세
데이터가 워낙 많아서 SYSTIMESTAMP로 분/초단위로 관리하는 추세
날짜 관련 함수는. 특히 그냥 이런 게 있구나 정도로 알아두자
JAVA에도 있고 DB에도 있는 기능은 JAVA에서 보통 한다..
1. EXTRACT : 추출
- EXTRACT( YEAR FROM SYSTIMESTAMP ) ==== 출력 결과 ===> 2022
- YEAR 대신 [ HOUR, MINUTE, SECONE, DAY, MONTH ] 다 가능
- 이런 걸 DB에서 사용하는 경우는 흔치 않다. JAVA에서 처리한다 보통
2. NEXT_DAY : 오늘을 기준으로 가장 가까운 요일을 찾는 함수
NEXT_DAY( SYSDATE, '토' ) ==== 출력 결과 ===> 22/05/21
3. TO_DATE : 날짜로 변환
TO_DATE( '22/05/19' ) ==== 출력 결과 ===> 22/05/19 ( DATE타입으로 변환 )
4. BETWEEN : 날짜와 날짜 사이 계산
MONTHS_BETWEEN( SYSDATE, TO_DATE('2021.05.19')) ==== 출력 결과 ===> 12
5. LAST_DAY : 현재 월의 마지막이 며칠인지 알려줌
LAST_DAY( '2022-2-3' ) ==== 출력 결과 ===> 22/02/28
6. ROUND : 현재 날짜에서 2번째 입력값을 기준으로 반올림해준다.
ROUND( SYSDATE, 'MONTH' ) ==== 출력 결과 ===> 22/06/01
'YEAR'도 가능.
[ 타입 변환 ]
1. TO_DATE
- TO_DATE( '2022-05-19 ' ) ==== 출력 결과 ===> 22/05/19
- 띄어쓰기, /(슬러시), .(점), -(작대기) :: 4개 중에 편한 걸로 표시
2. TO_NUMBER
- TO_NUMBER( '123' ) ==== 출력 결과 ===> 123
- 오른쪽 정렬 확인 - 숫자구나 CHECK
3. TO_CHAR
- TO_CHAR( SYSDATE ) ==== 출력 결과 ===> 22/05/19
- RESULT SET 클릭해서 연필 모양 클릭 - 문자열인 것 확인
+@ 내가 원하는 형태의 문자열로 바꿔서 출력 – 출력 형식 지정
4. TO CHAR ( 문자 포맷 지정 )
- TO_CHAR(SYSDATE, 'YYYY"년"MM"월"DD"일"') ==== 출력 결과 ===> 2022년05월20일
5. TO CHAR ( 숫자 포맷 지정 )
- SELECT TO_CHAR(12345, '$9,999,999') || '원' ==== 출력 결과 ===> $12,345원
- 자릿수 부족하면 이상하게 나옴 - 맞춰주거나 가능하면 여유롭게 많이 써주는 거 추천
- 9로 표현하는 이유는? - ‘숫자 : 9‘로 약속.
[ NULL 처리 함수 ]
1. NVL : 칼럼, 널이면 0으로 출력하겠다
- NVL(COMM, 0) ==== 출력 결과 ===> COMM 칼럼에 NULL인 값이 0으로 바꿔서 출력됨
2. NVL2 : 칼럼이 NULL일 때와 아닐 때 나오는 값 지정 가능
- NVL2 ( 칼럼, NULL이 아니면 나올 값, NULL이면 나올 값 )
- NVL2( COMM, 1, 0 ) ==== 출력 결과 ===> COMM 칼럼에 - NULL이 아니면 1, NULL이면 0 출력
- 왜 굳이? - 보여줘야 하는 값에 연산이 들어가 있다? NVL2 써주는 것이 유리
3. NULLIF
- 인자 값 2개 받아서 같다고 한다면 NULL로 표시해주는 함수
- NULLIF( SAL, 800 ) ==== 출력 결과 ===> SAL이 800이면 NULL로 표시
- 이거보다도 조금 더 좋은 함수 있는데 보통은 그거를 많이 사용한다.
[ 조건문 ]
1. DECODE : 여러 개의 값이랑 비교해서 내가 원하는 값으로 출력
- DECODE(DEPTNO, 10, '영업1팀', 20, '영업2팀', 30, '영업3팀')
- 사용자에게 M/F 보다 -> 남성 / 여성 보여주도록 해주는 경우에 사용
- 기능은 좋은데 가독성이 별로다 해서 나온 게 밑에 거
2. CASE WHEN THEN END ( ELSE )

장점
가독성
>= < 이런 거 DECODE에서는 사용 못한다.. 여기서는 사용 가능
BETWEEN 이런 애들도
ELSE도 처리 가능~
[ 순위 함수 ]
- OVER ( )
- RANK( )
- DES_RANK( )
- PARTITION BY

잉? ORDER BY의 실행 순서가 제일 나중이라서 뒤죽박죽 되었다..
해결 방법은?
1. ROW NUMBER() OVER( 정렬하고 싶은 것 )
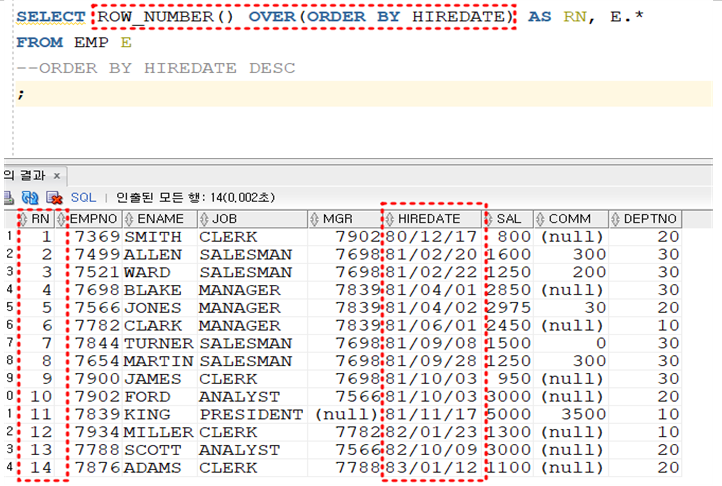
2. RANK( ) 로 대체 가능 – 대신 순위가 9 / 9 로 나온다.

3. DENSE_RANK( ) 도 사용 가능 – 동일한 거 나와도 다음 번호 삭제 안 하고 이어서

그룹 나눠서 랭크
부서별로 나눠서 랭크~
4. PARTITION BY

상황에 맞게 필요한 것 사용!!!!
[ 집계 함수 ]
COUNT ( ) : 행의 개수 세어주는 함수
- SELECT COUNT(*) FROM EMP ==== 출력 결과 ===> EMP테이블의 ROW개수
AVG( ) : 평균 구하는 함수
- AVG(SAL) ==== 출력 결과 ===> 2073.2142857142857142857
SUM
- SUM(SAL)
MIN
- MIN(SAL)
MAX
- MAX(SAL)
### 집계 함수는 결과를 출력할 때 한 칸으로만 출력을 해주는 것이 집계 함수
### 그룹 함수는 다르다.
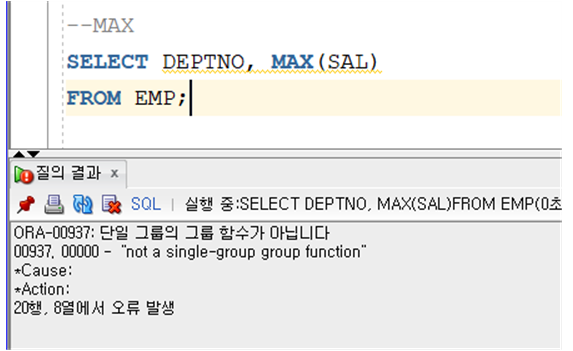
그룹을 나누고 해야 한다.
[ 그룹 함수 ]
그룹 나누기
- 한 개의 덩어리를 그룹별로 덩어리를 나누겠다.
- GROUP BY를 사용할 때는 ( SELECT에 집계 함수와 GROUP BY기준이 되었던 애만 사용 가능 )
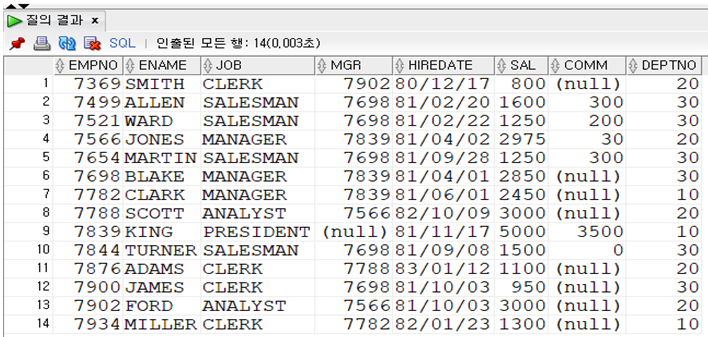
부서가 총 3개 있다. [ 10, 20 , 30 ]
부서 번호를 가지고 쪼개갰다.

AVG( ) 함수 사용했는데 한 칸이 아니라 3개의 결과가 나왔네? 무슨 일이?
한 덩어리였던 테이블을 GROUP 조건에 맞는 애들로 그룹을 나눈다.
부서 번호로 쪼갠다음에– 3개 그룹 생성 – 각각의 AVG를 구한 것이다.
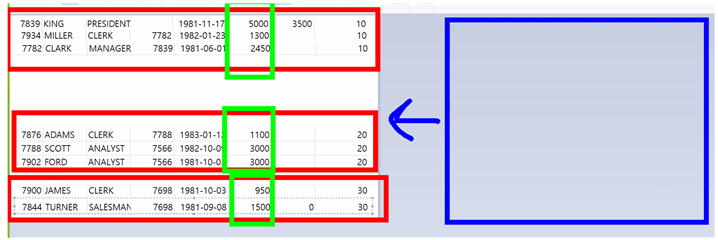
GROUP BY 가 없을 때는 전체 결과를 가지고 AVG 평균을 구한 것이었다.

그룹의 기준이 되었던 DEPTNO은 가능
- 그룹 한 덩어리의 결과가 하나하나 3개 출력되는 것이다.
- 그룹을 나누는 기준인 DEPTNO도 3개이고! 각 그룹의 DEPTNO은 동일! 3개 출력
- 3개 3개 맞다. 출력 가능

ENAME은 불가능 ( 정사각형 안된다. )
- GROUP 3개의 덩어리의 AVG의 결과는 3줄 – ENAME은 14줄
- 거기에다가 3줄 3줄 이더라도 – 누구의 ENAME을 가져와야 할지 모른다
- 동일하지 않으므로.. 출력 불가능



[ HAVING ]
- 테이블에서 RESULT SET으로 옮길 때는 SELECT 조건을 보는 것이 맞다
- RESULT SET에 들어온 애들을 그룹BY로 몇 개의 덩어리로 쪼갰는데
- 그 덩어리 안에(== 그룹핑된 )애들 중에 조건에 맞는 애들로만 보겠다.
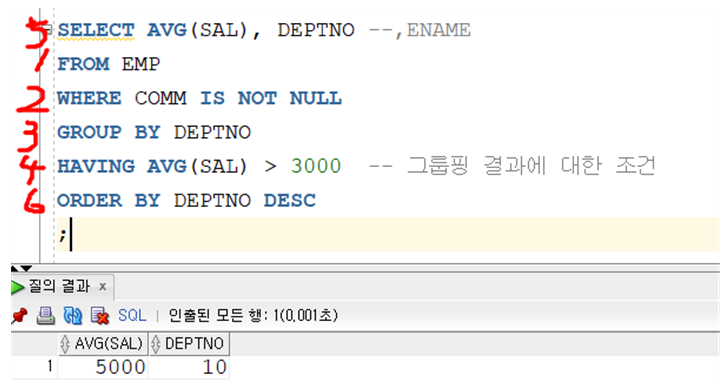
실행 순서
- FROM – WHERE – GROUP BY – HAVING – SELECT – ORDER BY
진도
[ 서브 쿼리 ]
- RESULT SET을 테이블처럼 사용
- RESULT SET을 얻기 위해선 SELECT 쿼리 하나 날려야 한다.
- FROM 절에 테이블 대신 RESULT SET을 사용
문제 발생
- WHERE, GROUP BY, HAVING 절에서는 별칭 사용 불가능하다.
왜?
- 별칭을 부여하는 SELECT 실행 전에 실행되는 WHERE절에서 별칭 사용 불가능
서브 쿼리란?
- FROM 절 뒤에 테이블이 와야 하는데
- 테이블처럼 똑같은 모양을 가지고 있는 RESULT SET애를 넣어줘도 된다.
- 이렇게 RESULT SET의 결과를 가져오는 쿼리를 서브 쿼리라고 한다!
- 하나의 쿼리 문의 실행결과 RESULT SET도
- 하나의 TABLE처럼 - 칼럼 있고 데이터도 들어있다.
- 즉, RESULT SET = TABLE 이랑 생긴 것이 다를 것이 없다.
문제 해결!
- 이런 식으로 서브 쿼리를 사용해주면
- WHERE, GROUP BY, HAVING 절에서 별칭 사용 가능!
- WHERE, GROUP BY, HAVING 절에서는 부여한 별칭으로만 조회 가능!
- 기존 TABLE의 칼럼으로는 조회 불가능!

REVIEW
ORACLE의 여러 가지 함수들을 하나하나
직접 사용해보며 사용방법과 출력 결과를 확인해보았다.
JAVA와 비슷한 함수도 있었고
새로 보는 함수도 많았다.
어떤 기능이 가능한지 체크해놓는 것이 제일 중요한 듯!
쿼리의 실행 순서도 배웠다.
S-F-W-G-H-O 자격증 준비하며 배운 문법 ㅎㅎ
실행 순서와 작동하는 것까지는 몰랐는데 이제 알게 되었다.
GROUP BY가 단순히 내가 보고 싶은
그룹만 지정해서 보여주는 것이라 생각했는데
집계 함수들과 같이 사용해보니
어떻게 작동하는지 어떤 의미인지 정확히 파악할 수 있었다.
SUB QUERY
저번 시간 ROWNUM의 별칭을 사용할 때 해보았던 ㅎㅎ
이게 서브 쿼리였구나~
SELECT쿼리 하나 실행해서 나온 RESULT SET을
TABLE처럼 사용해주는 것!
이번 시간에는 개념이 어려웠다기보다는
함수들을 따라서 실행해보고 하는 과정이 길고 힘들었다 ^-^
남은 DB과정도 화이팅!
'Java 기반 클라우드 융합 개발자 과정 - KH 정보교육원 > 5월' 카테고리의 다른 글
| 22. 05. 23 - 3차 시험! - 데이터베이스 구현 test (0) | 2022.05.25 |
|---|---|
| 22. 05. 20 - JOIN [ INNER, OUTER ] 집합연산자(UNION, INTERSECT, UNIONALL, MINUS ) (0) | 2022.05.24 |
| 22.05.18 - jdbc ( Connection, Statement, ResultSet ) (0) | 2022.05.19 |
| 22.05.18 - 정규표현식, ORDER BY, ROWNUM, DISTINCT (0) | 2022.05.19 |
| 22. 05. 17 - 트랜잭션(COMMIT, ROLLBACK), DDL, DCL, 연산자 (0) | 2022.05.18 |