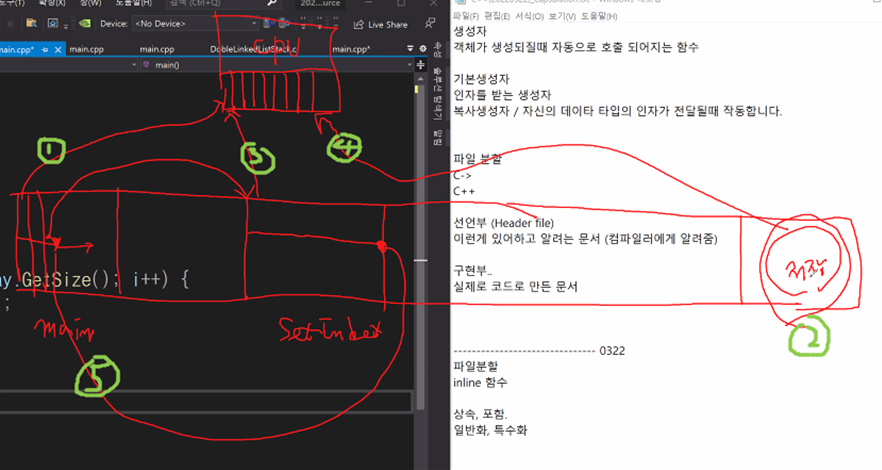
파일 분할
- 지금까지 실습하면서 새로운 오브젝트를 만들고 클래스를 만들 때마다
- main.cpp 파일을 매번 만들어서 그 안에서 클래스를 만들고 함수를 선언하고 구현해서 실습했었다.
- 요즘 언어들은 선언부와 구현부를 같이 만든다.
BUT!
C와 C++ 은 태생적으로 선언부와 구현부를 구별해서 - 파일 분할 형식으로 만든다!
- 선언부란? - 이런 게 있어; 하고 알려주는 문서 – 컴파일러에게 알려줌
- 구현부란? - 선언부의 그 문서를 실제 구현한 문서 - 실제 코드로 만든 문서
이처럼 파일 분할 형식으로 선언부와 구현부를 구별해서 만들기 때문에
- 선언부를 저장하는 헤더(. h ) 파일
- 구현부를 저장하는 클래스(. cpp ) 파일
- 2가지로 나눈다.
- 이처럼 나눠서 컴파일하는 것이 => 분할 컴파일
실습 순서 큰 틀 잡기 -
1. main.cpp 파일 만들어서 코드 싹 다 입력 - class 부분 / main 부분 다 입력
2. 헤더 파일 만들기 - main.cpp에 있는 class 부분만 긁어와서 넣어준다.
3. main.cpp 에있는 main부분에서 오류 난다. - 사용한 클래스나 함수들이 어디에 있는 누구의 것인지 몰라서
4. #include "DynamicArray.h"로 위치 알려준다. - < >는 기본적으로 제공되는 파일, " " 는 사용자가 만든 파일
5. DynamicArray.cpp 파일을 만들어서 DynamicArray.h 에 있는 함수의 구현 부를 가져온다.
6. h 파일에는 선언부가 //. cpp파일에는 구현부가 위치하도록 해준다.
클래스 부분과 메인 부분이 같이 있는 main.cpp 파일이 있다. - 파일 분할해보자
#pragma once
#include <iostream>
using namespace std;
// 클래스 부분
class DynamicArray {
private:
int _size;
int* _arr;
public:
DynamicArray(int size) {
_size = size;
_arr = new int[_size];
}
DynamicArray(DynamicArray& ref) {
cout << "복사생성자" << endl;
_size = ref._size;
_arr = new int[_size];
for (int i = 0; i < _size; i++) {
_arr[i] = ref._arr[i];
}
}
~DynamicArray() {
delete[] _arr;
}
int GetSize() {
return _size;
}
int GetIndex(int index) {
return _arr[index];
}
void SetIndex(int index, int value) {
_arr[index] = value;
}
void info() const {
for (int i = 0; i < _size; i++) {
cout << "array[" << i << "] = " << _arr[i] << endl;
}
}
};
//메인 부분
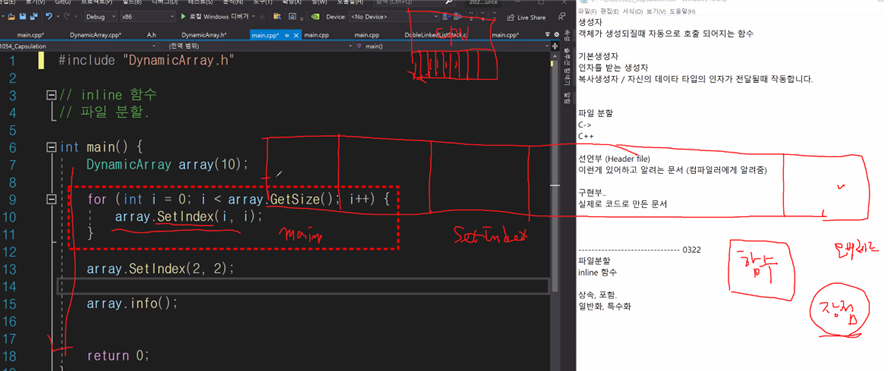
int main() {
DynamicArray array(10);
for (int i = 0; i < array.GetSize(); i++) {
array.SetIndex(i, i);
}
array.info();
return 0;
}
1. 헤더 파일을 만들고 - main.cpp에 있는 클래스 부분을 옮겨준다.

DynamicArray.h ---
#pragma once
#include <iostream>
using namespace std;
//클래스 부분
class DynamicArray {
private:
int _size;
int* _arr;
public:
DynamicArray(int size) {
_size = size;
_arr = new int[_size];
}
DynamicArray(DynamicArray& ref) {
cout << "복사생성자" << endl;
_size = ref._size;
_arr = new int[_size];
for (int i = 0; i < _size; i++) {
_arr[i] = ref._arr[i];
}
}
~DynamicArray() {
delete[] _arr;
}
int GetSize() {
return _size;
}
int GetIndex(int index) {
return _arr[index];
}
void SetIndex(int index, int value) {
_arr[index] = value;
}
void info() const {
for (int i = 0; i < _size; i++) {
cout << "array[" << i << "] = " << _arr[i] << endl;
}
}
};
2. 클래스 부분을 없애버려서 main.cpp에 오류 발생 - #include "DynamicArray.h"로 위치 알려주기
main.cpp ---
#include "DynamicArray.h"
//메인 부분
int main() {
DynamicArray array(10);
for (int i = 0; i < array.GetSize(); i++) {
array.SetIndex(i, i);
}
array.info();
return 0;
}
3. main.cpp 출력 확인

정상출력 확인
good :)
선언부와 구현부 분리해주기
DynamicArray.h 파일에 있는 함수 빼오기
1. DynamicArray.h 파일에 있는 함수 info( )를 - 새롭게 만든 DynamicArray.cpp파일에 옮겨주었다.

2. 어디에 있는 누구의 info( ) 인지 표시를 안 해주어서 오류남
- 클래스 밖으로 함수가 나온 경우 - 어디의 info ( ) 함수인지 알 수 없다.
- 어디에 속해있는 함수인지 지정 필요 - DynamicArray ::

3. DynamicArray.h 파일 - info( ) 함수 구현부{ }를 없애고 선언부만 놔두면 된다.

추가로 한 개 더 빼오면서 실습
DynamicArray.h에서 DynamicArray생성자 -> DynamicArray.cpp로 빼오기
- DynamicArray :: 로 표시 필요

DynamicArray.h에는 구현부 { } 없애주고 선언부만 표시해주기

이처럼
- DynamicArray . h --- ( 헤더 파일 )에는 선언부가 있고
- DynamicArray . cpp --- ( cpp파일 )에는 구현부가 있도록 구별해야 한다!
Question. : #pragma once?

Answer. 중복 포함하지 마라는 의미!!
A.h 파일 안에 #include "DynamicArray.h" 되어있는 상태인데

main.cpp에 와서 이렇게 #include "DynamicArray.h"와 #include "A.h" 해버리면

main.cpp는 DynamicArray.h 을 2번 포함하게 되는 것이다. - 있는 게 또 있다고 오류남
이런 상황을 막아주기 위해 #pragma once 사용하는 것 - 중복 포함하지 마라
inline함수
구현부와 선언부를 분리하는 특징은 C++ 특징 - java는 구현부 선언부 구분하지 않는다.
이처럼 함수를 - 구현부와 선언부로 분리해서 사용할 경우 - 2가지로 구분된다.
- 클래스 내부에 함수 선언해서 사용하는 경우
- 파일 분할 후 함수 꺼내와서 사용하는 경우
두 가지 경우 - 컴파일러는 각각 다른 요청으로 받아들인다.
클래스 내부에 선언하게 되면 inline 함수를 만들어 달라는 요청으로 받아들인다.
인라인 함수란?
- 프로그램의 실행 시간을 줄이기 위한 C++ 향상 기능.
- 함수는 호출되는 모든 위치에서 컴파일러가 해당 함수 정의를 대체할 수 있도록 - 함수를 인라인으로 만들도록 컴파일러에 지시할 수 있다.
- 컴파일러는 런타임에 함수 정의를 참조하는 대신, 컴파일 시간에 인라인 함수의 정의를 대체.
- 이것은 함수를 인라인으로 만들기 위해 컴파일러에 제안하는 것이다.
- 함수가 크면(실행 가능한 명령어 등의 측면에서) 컴파일러는 "인라인" 요청을 무시하고 함수를 일반 함수로 취급할 수 있다.
먼저 함수 호출 원리 Check

10번 Line - main에서 한 줄 한줄 쭉 실행 중에 SetIndex 함수 만나서 함수를 호출
-> 함수 위치로 명령 라인 넘어가서 쭉 실행하고
-> 다 끝나면 main에서 함수 실행 값 가지고 와서 적용
->11번 Line - 다음 라인부터 다시 쭉 실행
함수 호출 - 내부 로직 확인 - 메모리 상태 확인
① CPU는 main 에있는 명령어들 하나하나 읽어가면서 실행
② 함수 호출 라인으로 넘어가기 전에 메모리에다가 그 전까지 했던 작업들의 값을 따로 저장
③ CPU에서 Setindex 함수 쭉 실행
④ main으로 다시 넘어가기전에 저장해놨던 값으로 세팅
⑤ 함수 했던 거 적용
⑥ main에서 다음 라인부터 실행
만약 for문 안에 함수가 있다면?
for문으로 반복되는 동안 매번 SetIndex( )가 호출되는 것이고,
위의 ①②③④⑤ 번 과정이 계~속 반복되는 것이다. - 실행 시간 증가와 - 오버헤드 발생 가능성
이처럼 함수의 호출 비용이 크다는 것을 알 수 있다.
이러한 상황을 만들지 않기 위해 인라인 함수로 만들어달라고 요청
- 함수는 호출되는 모든 위치에서 컴파일러가 해당 함수 정의를 대체할 수 있도록
- 함수를 인라인으로 만들도록 컴파일러에 지시할 수 있다.
- 함수를 -> 인라인 함수로 만들도록 지시하는 방법이 - 함수를 클래스 내부에 선언해서 사용하는 것!
위에서 말한 -
클래스 내부에 함수를 선언하게 되면 inline 함수를 만들어 달라는 요청으로 받아들인다.
이 말의 의미를 이해할 수 있었다.
먼저 SetIndex( ) 함수 확인

클래스 내부에 함수를 만들면 inline 함수를 만들어달라 - 요청하는 의미로 받아들인다.

SetIndex 함수를 호출했을 경우
1번은 함수 호출로 적용했을 경우 - 적용 코드
2번은 인라인 함수로 적용 - 코드를 박아버렸을 때 - 적용 코드
정리 --
- 이처럼 C++ 인라인 함수는 대안을 제공한다.
- 인라인 키워드를 사용하여 - 컴파일러는 함수 호출 문을 함수 코드 자체로 대체한 다음 - 전체 코드를 컴파일합니다.
- 컴파일러가 상태를 보고 코드박을 수 있으면 코드로 , 안될 거 같으면 함수 호출로 해준다.
review
이번 시간에는 파일 분할과 inline함수에 대하여 배웠다.
파일 분할이라는 개념이 신기하였다.
java에서 클래스 부분을 따로 만들고 main 있는 클래스를 또 만들어서
거기서 출력하는 방식과 비슷한 느낌이었다.
추가된 개념은
헤더 파일에는 선언부를, cpp파일에는 구현부를 나눠서 따로 관리하는 점이었다.
이렇게 관리하는 이유는 아무래도 기능 추가나 유지보수 측면에서 좋아서인 것 같다.
디버깅 관련해서는 아직 어떤 이점이 있는지 모르겠다. ㅎㅎ
인라인 부분도 재미있었다.
함수를 호출하는데 저런 과정이 있는지 알 수 있어서 신기하였고
함수 호출 비용이 크다는 것도 알게 되었다.
한 두 번이야 별 차이가 없겠지만 이것이 반복되거나 처리량이 많아지면
0.01초가 100번만 쌓여도 1초. 천 번, 만 번이라면? 오우.
큰 관점에서 생각하는 습관 중요!
외부에 선언된 함수도 inline 키워드를 사용해 inline함수로 요청하는 부분도 있는데
그 부분은 더 check 해봐야겠다.
'Back-end > C++' 카테고리의 다른 글
| 22. 03. 24 - 상속(특수화) : 동물 육성 게임, string 클래스 기능 추가 상속 (0) | 2022.04.02 |
|---|---|
| 22. 03. 23 - 캡슐화, 상속(일반화) : 동물 육성 게임 (0) | 2022.04.02 |
| 22.03.21. 복사 생성자, const함수 (0) | 2022.04.02 |
| 22.03.18 - 동적 객체 배열, C언어 형식 지정 문자열, 동적 객체 포인터 배열 (0) | 2022.03.25 |
| 21.03.17 - 객체 배열, 동적 객체, 개념 플러스(GC,Malloc,Cin) (0) | 2022.03.24 |